AI workflowLLMSoftware deliveryAI agentsSDLC
Od Vibe Coding do AI Workflow: Co steruje agentem?
DC
Dominik Czerwiński
· 14 min czytania
W pierwszym wpisie wyjaśniałem, dlaczego sam prompt nie wystarcza w większym projekcie. Naturalny kolejny krok to agent, ale to słowo bywa używane bardzo szeroko. Zanim zaczniemy mówić o narzędziach i konfiguracji, trzeba uporządkować, czym właściwie jest agent w pracy z AI.
Czym właściwie jest agent AI?
Nie ma jednej definicji agenta, która działałaby tak samo w każdym narzędziu. Na potrzeby tego wpisu dobrym punktem startowym jest definicja z OpenAI:Agents are the core building block in your apps. An agent is a large language model (LLM) configured with instructions, tools, and optional runtime behavior such as handoffs, guardrails, and structured outputs.
Agent jako koncepcja, nie implementacja
Nie traktuję tutaj agenta jako konkretnego pliku, trybu w IDE ani funkcji jednego narzędzia. Ten sam mechanizm może być inaczej opakowany w Copilocie, Claude Code czy aplikacji zbudowanej bezpośrednio na SDK. Nazwy plików, trybów i ustawień będą się różnić, ale nadal chodzi o ten sam problem: jak sterować pracą modelu, kontekstem, narzędziami, ograniczeniami i outputem.Co wpływa na pracę agenta AI?
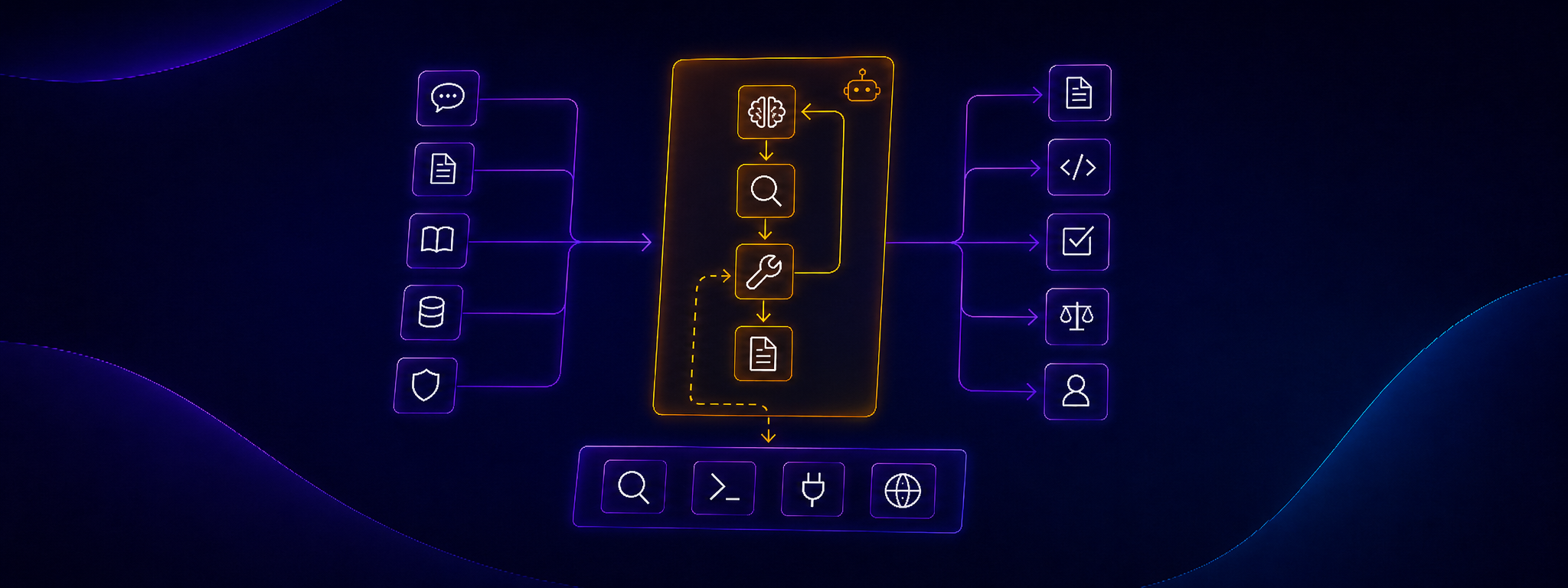
Skoro agent nie jest tylko modelem ani pojedynczym promptem, rozróżniam kilka grup elementów, które wpływają na jego pracę. Nie traktuję tego jako oficjalnej taksonomii z dokumentacji jednego narzędzia. To praktyczny model, który pomaga sprawdzić, czy agent ma właściwą konfigurację, właściwy kontekst i jasne granice pracy.Konfiguracja agenta
To elementy, które definiują sposób pracy agenta niezależnie od konkretnego zadania.- Model - wybór modelu wpływa na koszt, szybkość, jakość rozumowania i sensowny zakres odpowiedzialności. Innego modelu można użyć do eksploracji, innego do implementacji, a innego do review architektury.
- Rola i odpowiedzialność - agent powinien mieć zdefiniowane, czy ma eksplorować, przygotować specyfikację, implementować, zrobić review, czy tylko odpowiedzieć na pytanie.
- Instrukcje stałe (system instructions / system prompt) - reguły obowiązujące zawsze albo w danym typie pracy: wymagania architektoniczne, styl testów, konwencje projektu, sposób komunikacji i zasady formatowania outputu.
- Zasady szukania kontekstu (context discovery / retrieval guidance) - wytyczne określające, gdzie agent ma szukać brakujących informacji, z jakich źródeł ma korzystać i kiedy powinien przerwać exploration.
- Narzędzia i uprawnienia (tools / tool definitions) - dostęp do plików, edycji, terminala, testów, MCP, API albo innych źródeł. Sam LLM nie wykonuje tych akcji. Robi to runtime, który udostępnia narzędzia i egzekwuje część ograniczeń.
- Oczekiwany output - informacja, co agent ma zostawić po sobie: kod, specyfikację, summary, wynik weryfikacji albo materiał dla kolejnego kroku.
Input konkretnego zadania
To rzeczy, które agent dostaje na starcie danej pracy.- Prompt użytkownika - bieżące polecenie, czyli co ma zostać zrobione teraz.
- Kontekst zadania - ticket, acceptance criteria, opis błędu, otwarte pliki, aktualny diff, specyfikacja albo wcześniejszy artefakt.
- Instrukcje lokalne - reguły dotyczące tylko tego zadania, na przykład zakres zmiany, ograniczenia albo miejsca, których nie należy ruszać.
- Handoff z poprzedniego kroku - materiał wejściowy powstały wcześniej, na przykład specyfikacja, exploration summary, review notes albo wynik wcześniejszej sesji.
Kontekst pozyskany w trakcie pracy
To elementy, których agent nie musi znać na starcie, ale które może znaleźć albo otrzymać podczas działania. W terminologii systemów agentowych można myśleć o tym jako o retrieved context i obserwacjach z narzędzi, a nie jako o ręcznie przygotowanym prompcie.- Pliki i dokumenty (retrieved context) - fragmenty kodu, dokumentacja, konfiguracje, testy albo inne materiały odczytane w trakcie pracy.
- Wyniki narzędzi (tool results / observations) - output wyszukiwania, komend, testów, builda, lintera albo zewnętrznych API.
- Błędy i ograniczenia odkryte po drodze - brakujące zależności, niespójności w kodzie, nieaktualna dokumentacja albo przypadki, których nie było w początkowym opisie zadania.
Output i artefakty
To, co agent tworzy albo zostawia po sobie.- Zmiany w projekcie - kod, testy, konfiguracja, dokumentacja albo inne zmodyfikowane pliki.
- Podsumowania i notatki (working notes / intermediate artifacts) - implementation summary, decision notes, exploration summary, review findings albo wynik analizy.
- Handoff artifact - output przygotowany po to, żeby stał się inputem kolejnego kroku, agenta albo sesji.
Guardrails i weryfikacja
To elementy, które ograniczają pracę agenta albo sprawdzają jej wynik.- Guardrails - zasady mówiące, czego agent nie powinien robić albo co wymaga zatwierdzenia: zakazane pliki, destrukcyjne komendy, zmiany publicznego API, dostęp do danych wrażliwych, operacje poza zakresem zadania.
- Weryfikacja techniczna - testy, build, lint, typecheck, walidacja schematu albo inne automatyczne sprawdzenia.
- Weryfikacja merytoryczna - acceptance criteria, review architektury, zgodność z wymaganiami, zgodność z decyzjami projektowymi.
Jak faktycznie działa agent AI?
Skoro wiemy już, jakie elementy wpływają na pracę agenta, warto zobaczyć, jak układają się one w czasie. Agent nie działa jako jedna długa, ciągła myśl modelu. W praktyce jest to pętla między runtime'em, modelem i narzędziami. Runtime to warstwa sterująca: CLI, IDE, aplikacja webowa, framework agentowy albo własny skrypt. To ona odpowiada za techniczną stronę pracy agenta: przygotowanie wejścia dla modelu, obsługę narzędzi, przekazywanie wyników i egzekwowanie części ograniczeń. W uproszczeniu wygląda to tak:- Runtime składa wejście dla modelu. Bierze konfigurację agenta, input zadania, dostępny kontekst, historię sesji i opis narzędzi, z których agent może skorzystać.
- Model analizuje ten stan i generuje kolejny krok. Może odpowiedzieć tekstem, zaproponować zmianę albo zwrócić żądanie użycia narzędzia.
- Jeśli potrzebne jest narzędzie, model nie wykonuje operacji samodzielnie. Zwraca do runtime'u ustrukturyzowane żądanie wywołania narzędzia (tool call), na przykład odczytania pliku, wyszukania fragmentu kodu albo uruchomienia testów.
- Runtime wykonuje akcję poza modelem. To on czyta plik, odpala komendę, wywołuje API albo korzysta z MCP. To również runtime pilnuje uprawnień i może zatrzymać operację, jeśli wykracza poza dozwolony zakres.
- Wynik narzędzia wraca do kolejnego kroku. Runtime dokłada go do kontekstu i wysyła następne wejście do modelu. Od tego momentu model może pracować już na nowej informacji: znalezionym pliku, błędzie testu, wyniku wyszukiwania albo logu z komendy. Pętla zaczyna się od nowa.
Context flow, nie tylko input
Po opisaniu pętli runtime widać, że kontekst agenta nie jest stały. Z każdym krokiem może rosnąć o kolejne pliki, wyniki narzędzi, logi, błędy, zapisane decyzje i artefakty z poprzednich kroków.- Input powinien być dobrany do roli agenta. Spec writer potrzebuje innych informacji niż implementer, a reviewer innych niż explorer. Wrzucanie wszystkim wszystkiego może wyglądać bezpiecznie, ale często zwiększa szum i zużywa okno kontekstowe bez realnej korzyści.
- Exploration musi mieć granice. Agent powinien mieć określone, gdzie szukać, czego szukać i kiedy przestać. Bez tego może czytać dużo plików, znaleźć przypadkowe podobieństwa i zbudować wniosek na materiale, który nie ma znaczenia dla zadania.
Output, artefakty i handoff
Skoro agent działa w pętli, jego output nie powinien być traktowany wyłącznie jako końcowa odpowiedź. W pracy nad większym zadaniem output często pełni dwie role: jest wynikiem danego kroku i jednocześnie materiałem wejściowym dla kolejnego. Najbardziej oczywistym outputem jest kod, ale w pracy z agentami równie ważne są artefakty pośrednie. Nie chodzi jednak o dokumentację dla samej dokumentacji. Artefakt powinien pomagać w dalszej pracy, a nie tylko wyglądać jak ślad po wykonanym zadaniu. W praktyce artefakt powinien robić przynajmniej jedną z trzech rzeczy:- Ułatwiać review przez człowieka - dobry artefakt pokazuje rzeczy, które da się szybko sprawdzić: podjęte decyzje, założenia, przykładowe requesty API, diagram blokowy algorytmu, listę zmienionych obszarów albo przypadki brzegowe, które agent uwzględnił.
- Być precyzyjnym inputem dla kolejnego kroku - dobry artefakt powinien ograniczać konieczność odtwarzania ukrytej historii rozmowy. Kolejny agent, kolejna sesja albo człowiek powinien dostać jasny materiał wejściowy, a nie domyślać się, co właściwie było ustalone wcześniej.
- Wspierać kontrolę standardowego procesu SDLC - artefakt może zawierać wynik testów, status weryfikacji, listę niespełnionych acceptance criteria albo jednoznaczną rekomendację typu approve/reject. Dzięki temu łatwiej zatrzymać zmianę na review, w CI albo przed merge'em, zamiast przepychać błędny output dalej.
Zacznij prosto
Łatwo wpaść w pułapkę projektowania zbyt dużego workflow od pierwszego dnia. Skoro mamy agentów, tools, handoffy, guardrails i artefakty, to kuszące jest zbudowanie od razu całego procesu: agent od analizy, agent od specyfikacji, agent od implementacji, agent od testów i agent od review. Tylko że to często nie rozwiązuje problemu. Czasem jedynie przenosi chaos z jednego prompta do kilku nazwanych agentów. Na początku zwykle wystarczy jeden agent albo jeden prosty tryb pracy. Taki agent może przygotować zmianę, uruchomić testy i zrobić podstawowe self-review. W małym zadaniu to często jest wystarczające. Ważniejsze od liczby agentów jest to, czy agent ma jasno określone:- jaką rolę pełni,
- jakich reguł ma pilnować,
- gdzie ma szukać brakującego kontekstu,
- czego nie powinien robić,
- co ma zostawić po sobie,
- jak wynik ma zostać sprawdzony.