AI workflowLLMSoftware deliveryVibe codingSDLC
Od Vibe Coding do AI Workflow: Dlaczego sam prompt nie wystarcza?
DC
Dominik Czerwiński
· 10 min czytania
AI bardzo łatwo daje poczucie, że software development właśnie stał się prostszy. Wpisujesz prompt, dostajesz kod, a czasem nawet cały gotowy projekt. Przy małym projekcie albo izolowanym fragmencie systemu wszystko wygląda dobrze. Problem zaczyna się wtedy, gdy ten kod ma trafić nie do pustego repozytorium, tylko do realnego systemu, który ma już swoje zasady, historię i ograniczenia.
Vibe coding zachwyca. Na początku.
Łatwo zachwycić się AI, gdy jednym promptem dostajemy działający projekt. Monorepo, konfiguracja, paczki, przykładowa strona, kilka komponentów, podstawowy design system. Coś, co wcześniej zajmowało kilka godzin albo dni, pojawia się po chwili. Często w technologii, której jeszcze dobrze nie znamy, z bibliotekami, których wcześniej nie używaliśmy. Na początku wszystko wygląda obiecująco. Dodajemy pierwsze zmiany, poprawiamy szczegóły, dokładamy kolejne funkcje. Część rzeczy robimy ręcznie, coraz więcej zlecamy AI. Aplikacja rośnie, pojawiają się nowe ekrany, nowe komponenty, nowe przypadki użycia. Z zewnątrz wygląda to jak szybki postęp. Problem zaczyna się później, gdy zaczynamy uważniej patrzeć na całość. Jeden przycisk wygląda inaczej niż pozostałe. Nagłówki mają różne style. Walidacja w jednym miejscu działa inaczej niż w drugim. Jeden endpoint zwraca błędy w innym formacie niż reszta API. Testy sprawdzają szczegóły implementacji, ale nie zachowanie biznesowe. Każdy fragment osobno wygląda sensownie, ale razem tworzą system bez wyraźnych zasad. To nie są problemy stworzone przez AI. To problemy, które w projektach istniały wcześniej, tylko AI potrafi je bardzo szybko powielić i rozlać po większej części kodu. Wtedy zaczyna się druga faza pracy z AI: poprawianie poprawek. Prosimy o naprawienie jednego miejsca, potem o znalezienie podobnych przypadków, potem o ujednolicenie całej struktury. Każda kolejna iteracja coś poprawia, ale często przesuwa problem gdzie indziej. To jest moment, w którym pierwszy zachwyt zaczyna mijać. Nie dlatego, że AI przestaje być użyteczne. Raczej dlatego, że szybkie generowanie kodu zaczyna zderzać się z czymś dużo mniej widowiskowym: utrzymaniem spójności w systemie, który rośnie z każdą kolejną zmianą.Gdzie sam AI coding przestaje działać
Największy problem z samym promptowaniem nie polega na tym, że AI czasem się myli. Problem polega na tym, że bardzo łatwo oddajemy mu decyzje, których ono nie powinno podejmować samodzielnie. LLM nie pracuje z jednym, spójnym wyobrażeniem architektury naszej aplikacji. Jest uczony na ogromnej liczbie przykładów, pochodzących z różnych projektów, stylów, frameworków, bibliotek i sposobów organizacji kodu. Dlatego może zaproponować rozwiązanie, które samo w sobie wygląda sensownie, ale nie pasuje do naszego systemu. To nie musi być błąd modelu. Jeśli nie wskazaliśmy mu granic, zasad, oczekiwań i kontekstu projektu, to model wypełnia brakujące miejsca po swojemu. Czasem trafi. Czasem wybierze rozwiązanie popularne w internecie, bo dominuje w popularnych wątkach na Stack Overflow. Czasem wymiesza kilka podejść. A czasem zrobi coś, co wygląda poprawnie tylko do momentu pierwszej większej zmiany. W małym zadaniu to często nie przeszkadza - wrzucamy pytanie, dostajemy odpowiedź, poprawiamy detal i idziemy dalej. W większym systemie każde kolejne uruchomienie AI bez stabilnego kontekstu i zasad projektu może dawać lokalnie sensowny, ale globalnie niespójny wynik. Raz dostajemy inny podział odpowiedzialności, raz inną strukturę katalogów, raz inny styl walidacji, raz testy napisane według innej logiki niż poprzednio. Pojedynczy wynik może być poprawny, ale seria takich wyników zaczyna tworzyć dryf. I właśnie ten dryf jest kosztowny. Nie od razu, bo na początku wszystko wygląda jak przyspieszenie. Koszt pojawia się później: w poprawkach, niespójnościach, powielonej logice, testach, które trudno utrzymać, i decyzjach architektonicznych, których nikt świadomie nie zatwierdził.Problem nie leży w modelu
To nie jest problem, który rozwiąże sam większy kontekst, nowszy model albo dłuższy prompt. Większy kontekst pomaga, bo model widzi więcej kodu, decyzji i zależności. Ale sam nie wystarczy. Jeśli nie dostanie jasnych zasad projektu, nadal będzie zgadywał, tylko na podstawie większej liczby danych. Dlatego nie chodzi o to, żeby obrażać się na AI za wygenerowanie rozwiązania, które nie pasuje do naszego projektu. Model zwykle robi dokładnie to, do czego został zaprojektowany: generuje prawdopodobną odpowiedź na podstawie dostępnego kontekstu. Jeżeli ten kontekst jest niepełny, ogólny albo przypadkowy, odpowiedź też może być niepełna, ogólna albo przypadkowa. Z drugiej strony, gdy kontekst jest przeładowany, pojawia się inny problem: model zaczyna gubić istotne informacje, robić zbyt wiele rzeczy naraz i ignorować część instrukcji. Sam promptdodaj koszyk do aplikacji może być dobrym początkiem rozmowy, ale nie powinien być całym sposobem prowadzenia pracy. Problem nie leży w tym, że cel jest prosty. Problem zaczyna się wtedy, gdy nie mówimy modelowi, w jakiej roli ma pracować, jaką część zadania ma teraz rozwiązać, czego nie powinien ruszać i po czym sprawdzimy, że wynik pasuje do istniejącej aplikacji.
I tu zaczyna się różnica między promptem a procesem.
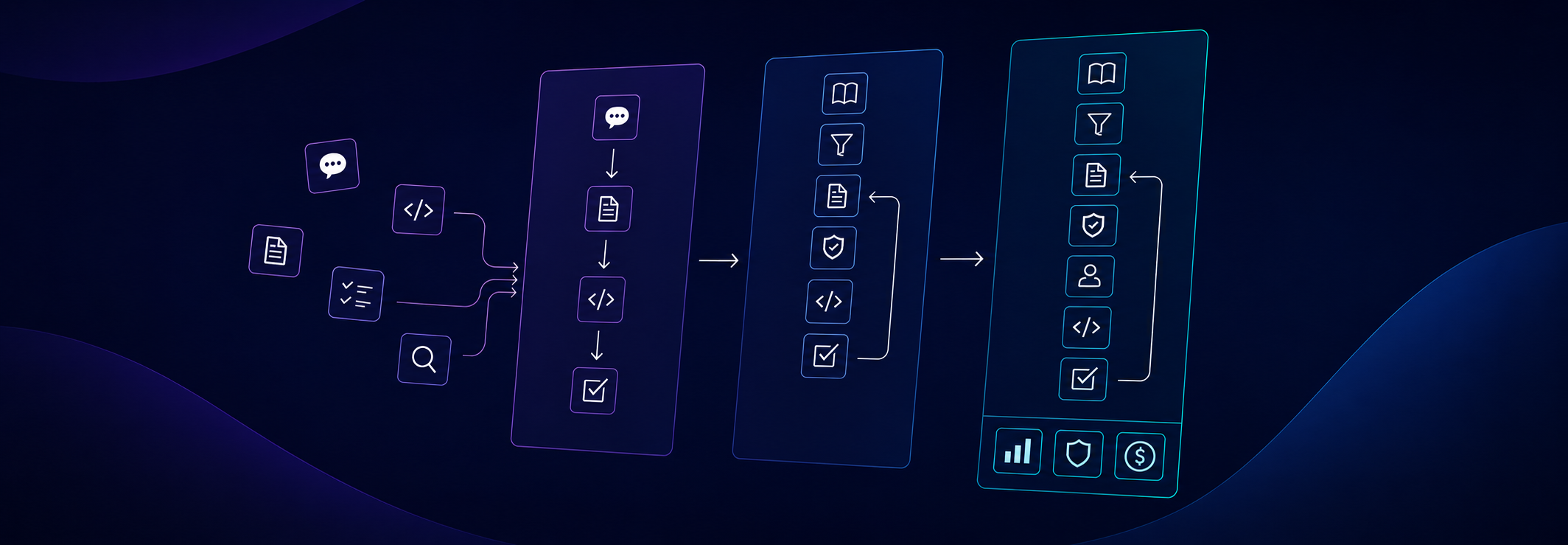
Od prompta do AI workflow: podstawowy flow
Nie chodzi o to, żeby wymyślić dla AI zupełnie nowy sposób tworzenia oprogramowania. Raczej o to, żeby odtworzyć minimalny proces, który i tak zwykle stosujemy, gdy pracujemy nad zmianą w istniejącym systemie. W normalnej pracy rzadko zaczynamy od samego kodu. Najpierw próbujemy zrozumieć, co ma powstać, dla kogo, z jakimi ograniczeniami i jak ta zmiana pasuje do reszty systemu. Dopiero później przechodzimy do implementacji, review i poprawek. To nie musi być ciężki proces. Nie chodzi o dokumentację dla samej dokumentacji ani o udawanie enterprise tam, gdzie wystarcza prosta zmiana. Chodzi o minimalny podział pracy, który ogranicza zgadywanie. W podstawowej wersji można rozbić to na kilka etapów:- zebranie wiedzy: co właściwie ma powstać, jakie są wymagania, reguły i ograniczenia;
- przygotowanie specyfikacji: jak ta zmiana pasuje do istniejącego systemu i jak ją zaimplementować;
- implementacja: przełożenie specyfikacji na kod;
- review: sprawdzenie, czy wynik pasuje do wymagań, architektury i zasad projektu.
- Knowledge Writer nie implementuje rozwiązania. Jego zadaniem jest zebrać i uporządkować wiedzę: wymagania, reguły biznesowe, kontekst domenowy, istniejące zachowania i decyzje, które mogą mieć wpływ na zmianę.
- Spec Writer bierze tę wiedzę i przekłada ją na plan pracy w konkretnym systemie albo repozytorium. To tutaj pojawiają się decyzje o tym, do jakiej warstwy powinna trafić zmiana, jakich komponentów dotkniemy, jakie API będzie potrzebne, jakie przypadki brzegowe trzeba obsłużyć i jak sprawdzimy poprawność rozwiązania.
- Implementer nie powinien na nowo wymyślać wymagań ani architektury. Jego zadaniem jest przełożyć specyfikację na kod, trzymając się zasad projektu. W zależności od flow może też przygotować testy albo zacząć od nich, jeśli pracujemy w wariancie TDD.
- Reviewer sprawdza efekt z innej perspektywy. Nie tylko czy kod się kompiluje, ale czy zmiana spełnia wymagania, pasuje do architektury, nie powiela logiki i nie wprowadza przypadkowego stylu obok istniejącego rozwiązania.
AI workflow to środek, nie cel
Samo wprowadzenie workflow do pracy z AI nie rozwiąże wszystkich problemów. Źle zaprojektowany proces może wręcz pogorszyć sytuację: podnieść koszty, wygenerować dokumentację, z której nikt nie korzysta, i dodać kolejne kroki bez realnej kontroli nad jakością. Dobry workflow powinien stabilizować pracę, a nie ją komplikować. Ma pomagać określić role, zakres odpowiedzialności, artefakty po każdym etapie i sposób weryfikacji wyniku. Powinien też dać się połączyć z tym, co już mamy w projekcie: testami, review, CI, lintingiem, analizą jakości czy zasadami architektury. Nie chodzi o zastąpienie SDLC, tylko o wpięcie pracy z AI w normalny proces dostarczania oprogramowania. Nie każdy projekt potrzebuje takiego samego flow. Skomplikowana domena biznesowa będzie wymagała więcej pracy nad wiedzą, regułami i przypadkami brzegowymi. Prosty CRUD albo pojedynczy ekran UI może potrzebować tylko lekkiej wersji tego procesu. Chodzi o to, żeby dobrać workflow do rozwiązywanego problemu, a nie budować procedurę dla samej procedury. Przy projektowaniu takiego flow warto szczególnie uważać na kilka obszarów:- Weryfikowalność - czy jesteśmy w stanie sprawdzić, że wygenerowany kod spełnia wymagania biznesowe, a nie tylko wygląda poprawnie?
- Zgodność z architekturą - czy AI nie wprowadza nowego stylu obok istniejącego rozwiązania? Czy reguły trafiają do właściwych warstw?
- Jakość kodu - czy nie powielamy logiki, nie ukrywamy złożoności i nie tworzymy kodu, którego za miesiąc nikt nie będzie chciał dotykać?
- Testy - czy testy sprawdzają zachowanie systemu, czy tylko aktualną implementację?
- Performance - czy rozwiązanie zadziała na realnych danych, a nie tylko na małym przykładzie z prompta?
- Koszt - ile kosztuje taki workflow: w tokenach, requestach, czasie review i utrzymaniu artefaktów?
- Security - jakie narzędzia udostępniamy AI, do jakich danych ma dostęp i jak ograniczamy ryzyko wycieku danych, szczególnie PII? Czasem problemem nie jest sam prompt, tylko narzędzie, które dostaje zbyt szeroki dostęp do repozytorium, logów albo danych testowych.